
武汉中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2020-10-29 来源:黑马程序员 浏览量:
以图1所示的Spark集群为例,阐述Standalone模式下,Spark集群的安装与配置方式。
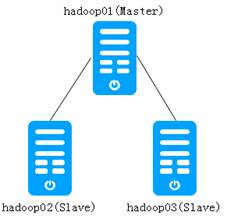
图1 Spark集群
从图1可以看出,我们要规划的Spark集群包含一台Master节点和两台Slave节点。其中,主机名hadoop01是Master节点,hadoop02和hadoop03是Slave节点。
接下来,分步骤演示Spark集群的安装与配置,具体如下。
1.下载Spark安装包
Spark是Apache基金会面向全球开源的产品之一,用户都可以从Apache Spark官网http://spark.apache.org/downloads.html下载使用。本书截稿时,Spark最新且稳定的版本是2.3.2,所以本书将以Spark2.3.2版本为例介绍Spark的安装。Spark安装包下载页面如图2所示。
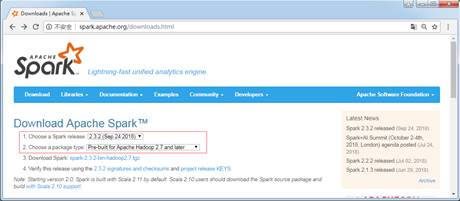
图2 Spark安装包下载
进入Spark下载页面,选择基于“Pre-built for Apache Hadoop 2.7 and later”的Spark2.3.2版本,这样做的目的是保证Spark版本与本书安装的Hadoop版本对应。
2.解压Spark安装包
首先将下载的[spark-2.3.2-bin-hadoop2.7.tgz](https://archive.apache.org/dist/spark/spark-2.3.2/spark-2.3.2-bin-hadoop2.7.tgz)安装包上传到主节点hadoop01的/export/software目录下,然后解压到/export/servers/目录,解压命令如下。
$ tar -zxvf spark-2.3.2-bin-hadoop2.7.tgz -C /export/servers/
为了便于后面操作,我们使用mv命令将Spark的目录重命名为spark,命令如下。
$ mv spark-2.3.2-bin-hadoop2.7/ spark
3.修改配置文件
(1)进入spark/conf目录修改Spark的配置文件spark-env.sh,将spark-env.sh.template配置模板文件复制一份并命名为spark-env.sh,具体命令如下。
$ cp spark-env.sh.template spark-env.sh
修改spark-env.sh文件,在该文件添加以下内容:
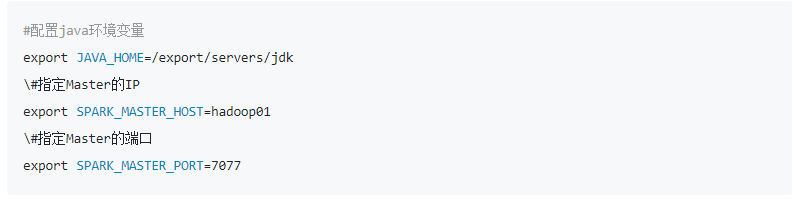
上述添加的配置参数主要包括JDK环境变量、Master节点的IP地址和Master端口号,由于当前节点服务器已经在/etc/hosts文件配置了IP和主机名的映射关系,因此可以直接填写主机名。
(2)复制slaves.template文件,并重命名为slaves,具体命令如下。
$ cp slaves.template slaves
(3)通过“vi slaves”命令编辑slaves配置文件,主要是指定Spark集群中的从节点IP,由于在hosts文件中已经配置了IP和主机名的映射关系,因此直接使用主机名代替IP,添加内容如下。
hadoop02
hadoop03
上述添加的内容,代表集群中的从节点为hadoop02和hadoop03。
4.分发文件
修改完成配置文件后,将spark目录分发至hadoop02和hadoop03节点,具体命令如下。
$ scp -r /export/servers/spark/ hadoop02:/export/servers/
$ scp -r /export/servers/spark/ hadoop03:/export/servers/
至此,Spark集群配置完成了。
5.启动Spark集群
Spark集群的启动方式和启动Hadoop集群方式类似,直接使用spark/sbin/start-all.sh脚本即可,在spark根目录下执行下列命令:
$ sbin/start-all.sh
执行命令后,如果没有提示异常错误信息则表示启动成功,如图3所示。
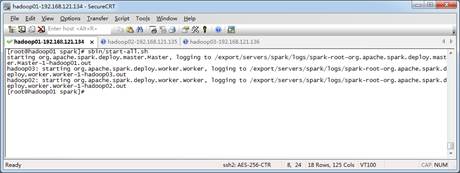
图3 启动Spark集群
启动成功后,使用Jps命令查看进程,如图4所示。
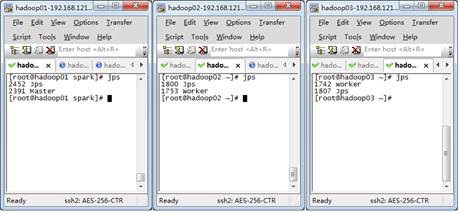
图4 查看集群进程
从图4可以看出,当前hadoop01主机启动了Master进程,hadoop02和hadoop03启动了Worker进程,访问Spark管理界面http://hadoop01:8080来查看集群状态(主节点),Spark集群管理界面如图5所示。
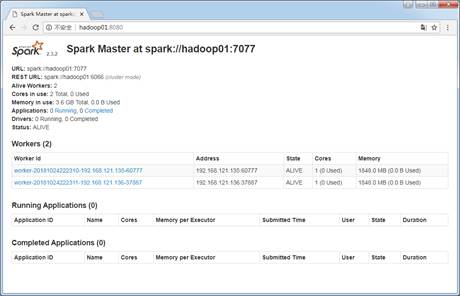
图5 Spark集群管理界面
至此,Spark集群安装完毕,为了在任何路径下可以执行Spark脚本程序,可以通过执行“vi /etc/profile”命令编辑profile文件,并在文件中配置Spark环境变量即可,这里就不再演示。
猜你喜欢:




















.jpg)