
武汉中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2020-11-12 来源:黑马程序员 浏览量:
在Map阶段输出可能会产生大量相同的数据,例如
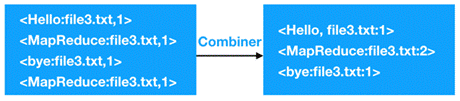
图1 Combiner组件的合并操作
Combiner组件是MapReduce程序中的一种重要的组件,如果想自定义Combiner,我们需要继承Reducer类,并且重写reduce()方法。接下来,我们针对词频统计案例编写一个Combiner组件,演示如何创建和使用Combiner组件,具体代码,如文件所示。
文件 WordCountCombiner.java
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class WordCountCombiner extends Reducer<Text,
IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values,
Reducer<Text, IntWritable, Text, IntWritable>.Context
context) throws IOException, InterruptedException {
// 局部汇总
int count = 0;
for (IntWritable v : values) {
count += v.get();
}
context.write(key, new IntWritable(count));
}
}文件是自定义Combiner类,它的作用就是将key相同的单词汇总(这与WordCountReducer类的reduce()方法相同,也可以直接指定WordCountReducer作为Combiner类),另外还需要在主运行类中为Job设置Combiner组件即可,具体代码如下:
wcjob.setCombinerClass(WordCountCombiner.class);
小提示:
执行MapReduce程序,添加与不添加Combiner结果是一致的。通俗的讲,无论调用多少次Combiner,Reduce的输出结果都是一样的,因为Combiner组件不允许改变业务逻辑。
猜你喜欢




















.jpg)