
武汉中心













 AI智能应用开发
AI智能应用开发 AI大模型开发
AI大模型开发 AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+
AI嵌入式+ AI大数据开发
AI大数据开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作运营
AI视频创作运营
免费领取黑马程序员AI通道专属星级课程资料

更新时间:2021-10-19 来源:黑马程序员 浏览量:
生产者先从 zookeeper 的 "/brokers/topics/主题名/partitions/分区名/state"节点找到该 partition 的leader.
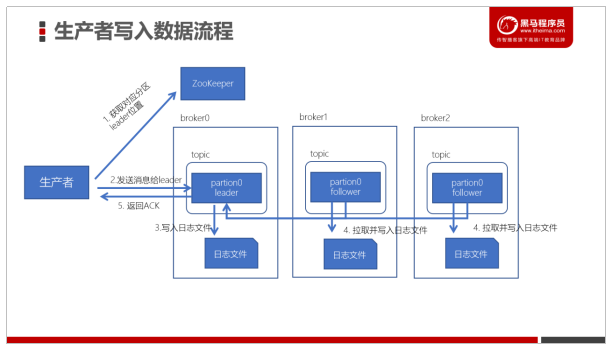
l 生产者在ZK中找到该ID找到对应的broker

l broker进程上的leader将消息写入到本地log中
l follower从leader上拉取消息,写入到本地log,并向leader发送ACK
l leader接收到所有的ISR中的Replica的ACK后,并向生产者返回ACK。

Kafka数据消费流程
有2种消费模式:
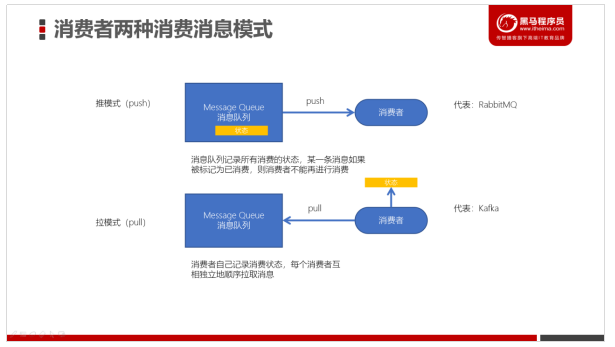
l kafka采用拉取模型,由消费者自己记录消费状态,每个消费者互相独立地顺序拉取每个分区的消息
l 消费者可以按照任意的顺序消费消息。比如,消费者可以重置到旧的偏移量,重新处理之前已经消费过的消息;或者直接跳到最近的位置,从当前的时刻开始消费。
Kafka消费数据流程
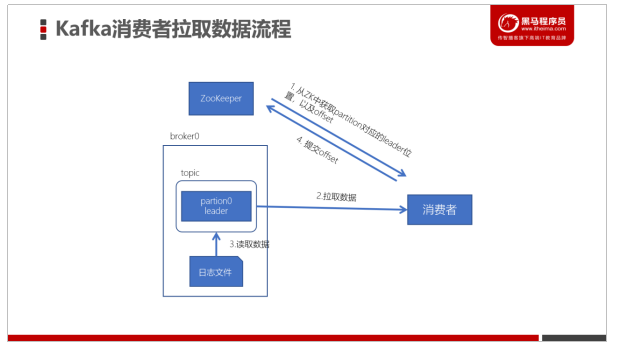
l 每个consumer都可以根据分配策略(默认RangeAssignor),获得要消费的分区
l 获取到consumer对应的offset(默认从ZK中获取上一次消费的offset)
l 找到该分区的leader,拉取数据
l 消费者提交offset
猜你喜欢:




















.jpg)